Python Web Framework: Flask Explained

Overview
When I worked at Dada Group, Flask was the most widely used web framework for the backend — from the staff system I was responsible for to the core delivery services. I studied Flask’s source code and learned about different server modes, as well as how Flask handles a request when it arrives at the server.
Different Kinds of Servers
Single-Threaded
A single-threaded server can handle only one request at a time. Other requests have to wait until the current one finishes. For the following codes, if a user requests /sleep which blocks for 10 seconds, a second user requesting /sleep during the time will have to wait.
from flask import Flask
import time
app = Flask(__name__)
@app.route("/sleep")
def want_to_sleep():
time.sleep(10)
return "sleep 10 seconds end"
if __name__ == "__main__":
app.run(debug=True, port=9000, threaded=False)Visualizing the Request Flow
Here is a text-based diagram to illustrate how the OS and the single-threaded Flask app handle multiple concurrent requests.
Time | Client Action | OS Kernel (TCP Backlog Queue) | Flask App (Single Thread)
-----------------------------------------------------------------------------------------
T=0s | User 1 -> GET /sleep | [ ] | Accepts & Processes Request 1 (Blocking)
| | | (time.sleep(10) starts)
| | |
T=1s | User 2 -> GET /sleep | [Request 2] | Still processing Request 1...
... | ... | ... | ...
T=10s| User 1 <- Response | | Finishes Request 1.
| | | Accepts & Processes Request 2 (Blocking)
| | | (time.sleep(10) starts)
... | ... | ... | ...
T=20s| User 2 <- Response | [ ] | Finishes Request 2.
| | |- Listening Socket: When the server starts, it creates a socket and tells the OS to listen for incoming connections on port: 9000.
- Kernel's Backlog Queue: The OS maintains a queue for this listening socket, called the backlog. When a new client sends a request, the OS performs the TCP handshake to establish a connection. Since the app is busy, the OS places this new, ready connection into the backlog queue.
- The accept() System Call: the server's main loop calls accept() to pull a connection from the queue. In a single-threaded model, the server is occupied with the first request(during time.sleep(10)) and cannot call accept() again until it's done. 4.Waiting in Line: The second user's request, now a fully established connection, simply waits in the kernel's queue. Once the first request is finished, the server's loop will call accept() again, and the OS will hand it the next connection from the queue.
Multi-Threaded
In multi-threaded mode, each request is handled in a separate thread. If a thread blocks (e.g., time.sleep(10)), other threads can still process new requests.
from flask import Flask
import time
app = Flask(__name__)
@app.route("/sleep")
def want_to_sleep():
time.sleep(10)
return "sleep 10 seconds end"
if __name__ == "__main__":
app.run(debug=True, port=9000, threaded=True)Visualizing the Multi-Threaded Flow
Time | Client Action | OS Kernel (TCP Backlog) | Flask App (Multiple Threads)
------------------------------------------------------------------------------------------------
T=0s | User 1 -> GET /sleep | [ ] | Accepts Request 1 -> Thread 1 starts processing
| | | (time.sleep(10) begins in Thread 1)
| | |
T=1s | User 2 -> GET /sleep | [ ] | Accepts Request 2 -> Thread 2 starts processing
| | | (time.sleep(10) begins in Thread 2)
... | ... | ... | ...
T=10s| User 1 <- Response | [ ] | Thread 1 finishes and sends response.
| | |
T=11s| User 2 <- Response | [ ] | Thread 2 finishes and sends response.
| | |A Note on the GIL: It's important to remember that due to Python's Global Interpreter Lock (GIL), multi-threading does not provide true parallelism for CPU-bound tasks. Only one thread can execute Python bytecode at a time. However, for I/O-bound applications like web servers, threads release the GIL while waiting for I/O, which is why this model provides a significant performance boost for handling concurrent requests.
How a Request Flows in Flask
When you create an app using app = Flask(name) and call app.run(), Flask uses Werkzeug’s built-in server to listen on a port, accept connections, and handle threads.
Here is a diagram about the whole process from a server start to deal with a request:
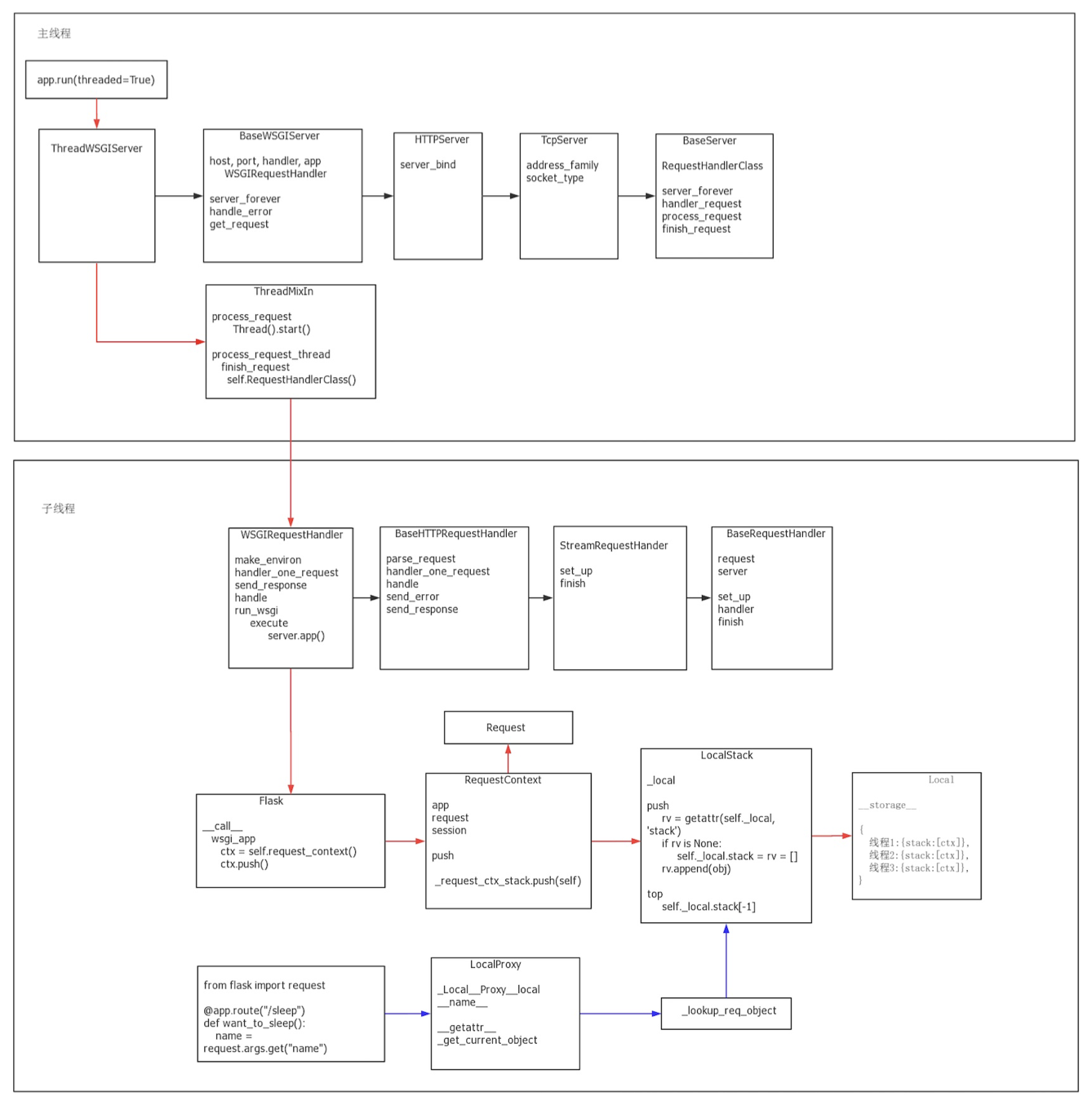
Request Lifecycle:
- Client sends HTTP request
- GET /hello HTTP/1.1 to localhost:9000.
- TCP layer receives the request
- The operating system delivers the request to the server socket that Flask’s TCPServer created.
- HTTPServer wraps the connection
- HTTPServer accepts the TCP connection and hands it to BaseWSGIServer.
- Threaded server handles the request
- Because threaded=True, ThreadingMixIn creates a new thread for this connection.
- Each thread will handle a single request independently.
- WSGIRequestHandler reads the request
- Parses the HTTP request line, headers, and body.
- Calls server.app(environ, start_response) to pass the request to Flask.
- Flask app receives it
- The call method of the Flask app receives a WSGI environ dictionary, which contains all request data (path, method, headers, body, etc.).
- Flask routing and view functions handle it and return a response.
- Response is sent back
- The server thread sends the HTTP response back over the same TCP connection to the client.
Other Ways to Handle Concurrent Requests
Multi-Process
The server creates multiple processes instead of threads. Each process handles requests independently.
- Pros: True parallelism (good for CPU-bound tasks), isolated memory.
- Cons: More memory usage, slower process creation.
Asynchronous / Event-driven (Async I/O)
The server is usually single-threaded but can handle many requests concurrently. How it works:
- Uses event-driven I/O: an event loop monitors multiple sockets and only acts when a socket is ready (read/write).
- Async code (async/await) pauses tasks while waiting for I/O, letting the server process other requests. Pros: Very memory-efficient for I/O-heavy workloads. Examples: Node.js, Python asyncio, FastAPI with async endpoints.
Hybrid
Combine processes, threads and/or async. Example: Gunicorn with multiple worker processes, each using threads or async workers.
How Flask Handles Global Variables in Threads
from flask import Flask
app = Flask(__name__)
current_user = None # global variable
@app.route("/set/<name>")
def set_user(name):
global current_user
current_user = name
return f"User set to {name}"
@app.route("/get")
def get_user():
return f"Current user: {current_user}"If two requests come in at the same time:
- Request A calls /set/Alice.
- Request B calls /set/Bob.
Since both requests share the same current_user global, the variable will be overwritten. Depending on timing, both users may see inconsistent results like:
- Alice sets the user, but gets back "Bob"
- Bob sets the user, but gets back "Alice"
Flask’s Solution: threading.local()
Instead of using true global variables, Flask provides context-local objects (like request, session, g). These are implemented using threading.local(), a Python utility that creates thread-local storage.
import threading
data = threading.local()
def worker(name):
data.value = name
print(f"{threading.current_thread().name} sees {data.value}")
t1 = threading.Thread(target=worker, args=("Alice",))
t2 = threading.Thread(target=worker, args=("Bob",))
t1.start()
t2.start()
t1.join()
t2.join()Even though both threads assign to data.value, each thread has its own independent copy. The variable data.value in Thread-1 is completely separate from data.value in Thread-2.
How Flask Uses It Internally
from werkzeug.local import Local
_request_ctx = Local()
# request object is stored here
_request_ctx.request = ...So each thread has its own request object (context-local)
from flask import request
@app.route("/")
def hello():
return request.pathAppContext
Besides RequestContext, like request, session, Flask provides g, a Application Context, which is also thread-local.
from flask import g
@app.route("/set/<name>")
def set_user(name):
g.user = name # stored in thread-local storage
return f"user set to {name}"
@app.route("/get")
def get_user():
return f"Current user: {getattr(g, 'user', None)}"Even if 10 users hit the server at the same time, each thread/request gets its own g.user, avoiding race conditions.
